Analyysiä hieman tarkennettu aamulla 27.9.2018.
Olen syntynyt 1980-luvulla. Muistelen lapsuuteni talvia lumisina ja kylminä. Samalla muistan tältä vuosikymmeneltä talvia, joilloin yhtäjaksoista pakkasjaksoa ei kestänyt kuin muutaman viikon, tai siltä ainakin tuntuu. Olen lähes koko ikäni ajanut kaikki arkimatkani talvisinkin polkupyörällä ja minusta tuntuu, että pyöräily Oulun talvessa on ollut tällä vuosikymmenellä vaikeampaa kuin koskaan ennen. Muutama vuosi sitten aloin käyttää ensimmäistä kertaa pyörässäni nastarenkaita, koska lämpimästä säästä johtuvia liukkaita kelejä oli niin paljon.
Oululaisen talven muutosta ei ole pakko mutuilla. Ilmatieteen laitoksen avoimesta datasta voidaan tehdä katsaus säähän pitkälle menneisyyteen. Olen löytänyt Oulusta säädataa vuodesta 1955 alkaen, mutta ainakin Helsingissä päästään pitkälle 1800-luvun puolelle. Datan nouto rajapinnalta onnistuu lähes leikiten, kun hyödyntää Mikko Marttilan R-pakettia fmir.
Katsotaan ensin tulokset ja vasta sitten ohjelmakoodia niiden takana.
Esitän seuraavassa kuvassa kuukauden keskilämpötilan kuukausittain alkaen vuodesta 1955 elokuuhun 2018 saakka. Olen sovittanut jokaisen kuukauden datalle erikseen lineaarisen regressiomallin. Kuvassa pisteet esittävät kuukausien keskilämpötiloja ja sininen viiva on kuukaudelle sovitetun lineaarisen regression regressiosuora. Esitän punaisella tekstillä kunkin kuukauden keskilämpötilan muutoksen, joka on kuukaudelle sovitetun mallin ennusteen loppupään ja alkupään erotus.
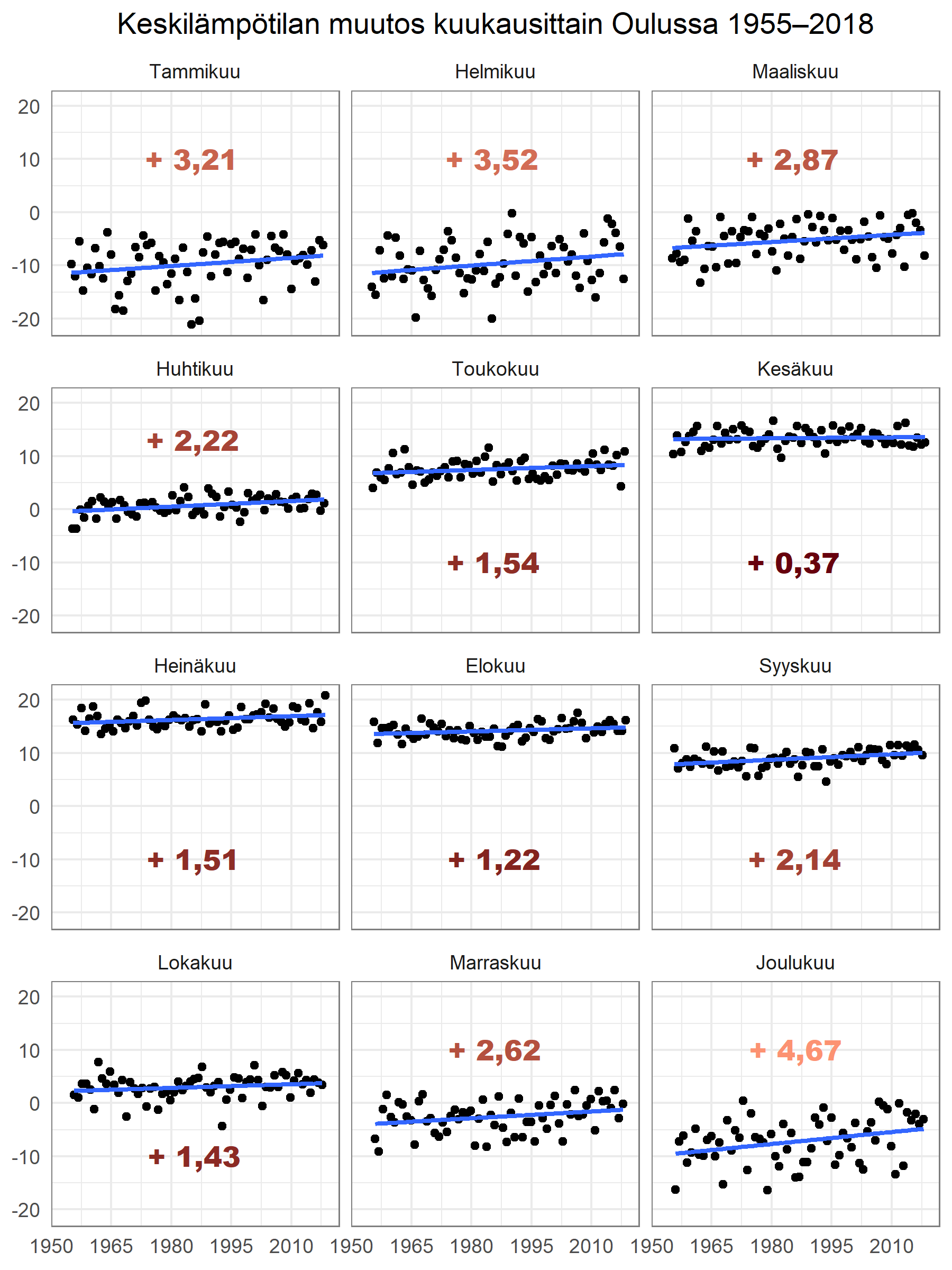 Kuvasta nähdään, että talvikuukausien lämpötila on noussut selvästi enemmän kuin kesän. Trendin ennustetaan jatkuvan. Mallien mukaan kaikkein eniten on lämmennyt joulukuu, joka on ollutkin tällä vuosituhannella todella lämmin.
Kuvasta nähdään, että talvikuukausien lämpötila on noussut selvästi enemmän kuin kesän. Trendin ennustetaan jatkuvan. Mallien mukaan kaikkein eniten on lämmennyt joulukuu, joka on ollutkin tällä vuosituhannella todella lämmin.
Kuvasta huomataan myös, että keskilämpötila vaihtelee talvisin huomattavasti enemmän kuin kesällä. Joulu–helmikuussa keskilämpötilan vaihteluväli on noin 15 astetta, kun kesäisin keskilämpötila vaihtelee alle kymmenen asteen sisällä. Talven sää paitsi lämpenee, on paljon sattuman varassa.
Analyysiäni ei voi pitää tieteellisenä vaan pikemminkin kuvailevana. Selvää lämpenemistä on kuitenkin tapahtunut. Lämpimien kuukausia on esiintynyt viime vuosina tiuhaan, paljon tiuhemmin kuin menneinä vuosikymmeninä.
Koodi
Data
Aivan aluksi tarvitaan Ilmatieteen laitoksen api-avain, jonka saa rekisteröitymällä palvelun käyttäjäksi. Sitten asennetaan fmir-paketti R:ään. Rtools tulee olla asennettuna, jotta githubista voi asentaa paketteja.
devtools::install_github("mikmart/fmir")Ladataan muutama paketti, asetetaan api-avain tehdään tibble päivämääriä varten. Kuukausittaisia tietoja voi poimia rajapinnalta viiden vuoden palasissa, joten alkupäiviä tehdään viiden vuoden välein.
library(lubridate)
library(tidyverse)
library(fmir)
library(magrittr)
fmi_set_key("avaimesi-tähän")
dates <- tibble(alku = make_date(seq(1950, 2015, 5)), loppu = alku + years(5) - days(1))Seuraavaksi luomme listan query-osotteita, jotka kukin palauttavat rajapinnalta yhden siivun dataa. Ensin kirjoitetaan funktio, jossa täytämme valmiiksi fmir-paketin fmi_query-funktion vakiona pysyvät argumentit. Tässä tapauksessa tosin vain tietotyyppi, joka on tässä "monthly", pysyy vakiona.
Jotta voidaan varmistaa ehjä data, poimitaan aineistoa kahdelta eri sääasemalta.
Päivämäärät on muutettava character-tyyppisiksi, koska pmap kärsii R:n bugista, jonka vuoksi date-tyypin vektoria ei voi käyttää, mutta luotaviin queryosoitteisiin muunnoksella ei ole vaikutusta.
pmap:lle ei tarvitse antaa sarakkeiden nimiä ollenkaan, jos sarakkeiden nimet vastaavat funktion argumenttien nimiä. Tässä ne ovat tahallaan samat.
ouluquery <- function(alku, loppu, paikka) {
fmi_query(place = paikka, type = "monthly", starttime = alku, endtime = loppu)
}
paikat <- c("Oulu", "Oulunsalo")
q_url <- dates %>%
crossing(paikka = paikat) %>%
mutate_at(vars(alku, loppu), as.character) %>% # jotta pmap toimii
pmap(ouluquery)Sitten imuroidaan data ja lasketaan kahden sijainnin välisille arvoille keskiarvo.
kkdata <- map(q_url, fmi_data) %>%
bind_rows()
kkdata <- kkdata %>%
select(-location) %>%
group_by(time) %>%
summarise_all(mean, na.rm = TRUE)Kuva
Kuvaa varten tarvitaan kaksi dataa: pisteiden ja regressiosuoran data sekä erotuksen data. Ensin lisätään dataan vuosi- ja kuukausi-sarakkeet. Toinen kuukausisarake on kuvan piirtämistä varten, toinen datan helppoa käsittelyä varten.
vuosidata <- kkdata %>%
mutate(month = month(time, label = TRUE, abbr = FALSE) %>% str_to_title() %>% as_factor(),
nummon = month(time),
year = year(time)) Sitten lasketaan kuvan jokaiseen paneeliin piirrettävä erotus. Ensin data pesästetään kuukauden mukaan ja sitten uusiin sarakkeisiin ajetaan ensin mallit ja toiseksi ennusteet. Jokaiselta kuukaudelta poimitaan ensimmäinen ja viimeinen rivi erotuksen laskemiseksi. Lopuksi luodaan päivämäärä datan keskipisteen tienoille vuoteen 1985 tekstin paikaksi x-akselilla.
erotus <- vuosidata %>%
filter(!is.na(tmon)) %>%
nest(-month) %>%
mutate(model = map(data, ~ lm(tmon ~ year, data = .)),
pred = map2(data, model, modelr::add_predictions)) %>%
unnest(pred) %>%
arrange(month, time) %>%
group_by(month) %>%
slice(c(1, n())) %>%
mutate(erotus = pred - lag(pred)) %>%
ungroup() %>%
filter(!is.na(erotus)) %>%
mutate(time = make_date(1985, month(time)))Kuvan pitkähkö koodi on ainakin minun Rstudiossani pakko ajaa maalaamalla se hiirellä kokonaan. Tavanomainen ctrl+enter ei toimi joka kohdassa koodia, koska ohjelma lukee jostain syystä case_when:in väärin. extrafont:n käytöstä kirjoitin viime viikolla.
library(extrafont)
p1 <- vuosidata %>%
arrange(time) %>%
mutate(time = as_date(time)) %>%
ggplot(aes(time, tmon)) +
facet_wrap(~ month, ncol = 3) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
geom_text(data = erotus, aes(y = case_when(
nummon %in% c(1:3, 11, 12) ~ 10,
nummon == 4 ~ 13,
TRUE ~ -10),
label = paste("+", format(round(erotus, 2), decimal.mark = ",")),
color = erotus), size = 4.5, family = "Arial Black", show.legend = FALSE) +
scale_color_gradient(low = "#67000D", high = "#FC9272") +
scale_x_date(date_breaks = "15 years", date_labels = "%Y", expand = expand_scale(c(0, 0.05))) +
theme_minimal() +
theme(panel.border = element_rect(color = "gray50", fill = "transparent"),
plot.title = element_text(hjust = 0.5)) +
labs(x = NULL, y = NULL,
title = "Keskilämpötilan muutos kuukausittain Oulussa 1955–2018")
ggsave("fig/kuva_2018_09.png", h = 8, w = 6)Huomasin vasta myöhemmin, että erotukset voisi laskea myös suoraan ggplot-objektista, johon on laskettu geom_smooth():
ggplot_build(p1)$data[[2]] %>%
as_tibble() %>%
arrange(PANEL, x) %>%
group_by(PANEL) %>%
slice(c(1, n())) %>%
mutate(erotus = y - lag(y)) %>%
filter(!is.na(erotus)) %>%
pull(erotus)
# [1] 3.2110343 3.5201236 2.8667801 2.2184819 1.5372393 0.3652941 1.5079642 1.2185229 2.1392907 1.4280882 2.6245573 4.6680225